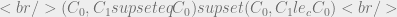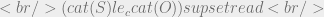In my last post on this topic, we got into what I would consider the second half of Multi-Level Security (MLS). Here we discussed categories, also known as compartments and how they relate to the security model itself. We then extended the short-hand logic adapted from Chu and Older to allow for reasoning through access control decisions regarding categories.
I’ll be following the format of my previous two posts under this tag, so in this post we’ll be getting our hands dirty in the SELinux MLS policy. We’ll go through these constraints and work through them using the logic hopefully making some sense of the rules and the policy they implement.
SELinux MLS Constraints
I think I covered enough background on SELinux to just dive into the specific constraints relevant to the policy we’ve been discussing. I’ve used file read / write in previous examples so we’ll stick to that again in this post. We’ll start with simple read case, then move on to conclude the discussion begun in my last post about constraints on categories for subjects writing data to objects. We may even see the “high-water mark” again 🙂
File Read MLS Constraint
Let’s begin with the SELinux mlsconstraint for read operations on files:
# the file "read" ops (note the check is dominance of the low level)
mlsconstrain { dir file lnk_file chr_file blk_file sock_file fifo_file } { read getattr execute }
(( l1 dom l2 ) or
(( t1 == mlsfilereadtoclr ) and ( h1 dom l2 )) or
( t1 == mlsfileread ) or
( t2 == mlstrustedobject ));
In a previous post I went blow by blow through each line of the constraint; we won’t bother with that again. Instead let’s look at the first line, which embodies the simple security property, and frame this in the logic we’ve recently expanded to reason over categories.
When we say that one label dominates another as in the dom operator from the constraint, both the sensitivity and the category component of the label must dominate. For the sensitivity we’ve established that the label set is a partial order where the  operator denotes dominance:
operator denotes dominance:

In my last post we discussed how dominance is proven for a category set. Specifically, the category set A dominates another set of categories B if A is a superset of B. We represent this in the logic with the same operator using a different subscript: 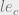
c to denote category instead of s for sensitivity.
With this new operator we can formalize the dom operator from the mlsconstrain but, if you’ve got a good eye for detail you’ve probably noticed that our logic doesn’t have the facilities to deal with SELinux MLS ranges. The MLS parameters from the mlsconstrain statements are either the high or low portion of the MLS range. To accommodate this we add subscripts l and h to the  and
and 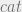 operators to access the low and high parts of the range respectively.
operators to access the low and high parts of the range respectively.
With these minor modifications we can represent the full logical expression that must be satisfied in order to conclude a read operation should be granted. Let’s call this implication the read implication for reference.

A Proof using the Read Implication
Any reasoning using this system must be done in the context of a specific example. Let’s construct one for a subject and object then work our way through using the read implication.
Our subjects MLS range will be:

And our objects MLS range will be only a single level as it’s very rare for a passive object on disk to have a high and low MLS component. We can think of this as the low and high MLS levels being the same:
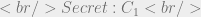
I’m not feeling very imaginative today as you can see by my categories simply being 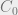 and
and  . Regardless we’ve got enough information to do begin a proof with the aims to satisfy the left side of the read implication, which, in plain english, requires that the subjects low MLS label must dominate that of the object.
. Regardless we’ve got enough information to do begin a proof with the aims to satisfy the left side of the read implication, which, in plain english, requires that the subjects low MLS label must dominate that of the object.
At this point the logic becomes a mechanical exercise in which we simply show that the dom relationship holds … I can see you getting bored but don’t worry, there is a twist but let’s start with our assumptions restated from above in something closer to the form we’d want in a proof:

Here’s the twist: we’ve got no way to reasonably conclude  from these assumptions. This is because we would need to derive the left side of the read implication from which we could conclude . We can however see from our given labels that:
from these assumptions. This is because we would need to derive the left side of the read implication from which we could conclude . We can however see from our given labels that:

and

Both the sensitivity and the category of the subject’s low MLS component DO NOT dominate that of the object. So what’s a subject to do?
Current Level vs Clearance
We need the subjects low MLS level to increase. The mechanics of how this happens and how it’s done in SELinux are out of scope here (that’s how I get out of describing something complicated) but let’s assume there’s a safe way for a subject to do this and that they can’t simply do so at will.
The low MLS level is often referred to as the users “current” level, and the high MLS level as the users “clearance”. The term “high-water mark” comes from the analogy made between the users current level rising as a result of subject actions and the mark made by rising water on a surface.
But I’m digressing. Now that our user can safely increase their current/low MLS level we can get back to our example.
Finally Reading the File
Let’s assume that our user can increase their low/current MLS label to the minimum possible for their access to be granted, assuming of course it will never exceed their clearance. We now use these values as the assumptions in our proof:

We then use these to show that the read should be allowed:

This is only the first of several logical constraints from the mlsconstraint for file read operations. In a previous post I’ve tried to fit SELinux types and comparisons there of into this logical framework but it’s not a very natural fit. Since this post is already getting close to 1200 words and we still haven’t talked about the constraint on write operations I’ll put off the discussion of types for now.
File Write MLS Constraint
Now that we’ve examined the read operation, it’s time to take on writing to files. The SELinux constraint for this case is as follows:
mlsconstrain { file lnk_file fifo_file dir chr_file blk_file sock_file } { write create setattr relabelfrom append unlink link rename mounton }
(( l1 eq l2 ) or
(( t1 == mlsfilewritetoclr ) and ( h1 dom l2 ) and ( l1 domby l2 )) or
(( t2 == mlsfilewriteinrange ) and ( l1 dom l2 ) and ( h1 domby h2 )) or
( t1 == mlsfilewrite ) or
( t2 == mlstrustedobject ));
Like before we’re going to ignore all except the first part of the constraint: l1 eq l2. This is the rule that implements the expected “high-water mark” behavior. The remaining parts of the constraint are relaxations of this rule and should be used with caution.
You’ll notice that the constraint for writing differs from reading. It doesn’t require l1 dom l2, instead the current MLS level for the subject must be equal to that of the object: l1 eq l2. But instead of introducing new logic to express equality, we’ll use the reflexive property of the and operators:

Notice this deals only with sensitivity so we’d have to show the same for the category component of the MLS label. Accounting for both sensitivity and categorys we would say that if  then the reference monitor can conclude
then the reference monitor can conclude 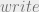 (allow the operation). We’ll call this implication the write implication for future reference:
(allow the operation). We’ll call this implication the write implication for future reference:

Let’s look at a write request in the context of the MLS ranges for our subject S and object O from the read example above. Again, we’re concerned with the low part of the MLS label so the assumptions are:

From the read example we know that initially the current MLS level for the subject doesn’t dominate that of the object:

so again we’re in the situation where the subect must increase it’s low MLS label to access the object O. Let’s assume this is possible but it’s not enough. We have to account for the category component as well and as we saw above, the category set of the subject and object must be the same. Our subject must then drop from its category set as well:

Now that we’ve increased the low (current) MLS label and dropped the required category from the subject S we can use the logic to prove that our reference monitor will allow the write operation using the write implication from above.

An operator to express equality among sensitivities and categories would only serve to shorted the conjunctions in the last two expressions so it may be useful, though only as syntatic sugar.
The High-Water Mark
Something that we glossed over are the implications of subject actions possibly resulting in a subjects current MLS level increasing. This is a reasonable requirement given that we don’t want to allow a subject to do something like reading a file in one category and then writing data from it to a file with a different category label. We must assume that when the system increases the current MLS level for a subject the operation is safe.
By “safe” we mean there would need to be mechanisms to prevent the user from:
- setting their low MLS level to anything above their high level
- that the high level is static and determined by the security administrator
- that the user cannot decrease their low MLS level without having their environment thoroughly scrubbed to prevent information leakage
These details are only peripheral to the main focus of this post but the details are often what make or break a system. Doing things like sanitizing a users environment to prevent data leakage can be extremely invasive and can disrupt the users work flow significantly.
Conclusion
There are two things to take away from this post one positive, one negative. First, the logic we’ve been using up to this point is able to represent the reasoning a reference monitor would do when evaluating either a read or a write an access request. This could be used to take a mechanical proof system and use it to implement the core of the SELinux reference monitor. That’s pretty cool.
The negative that’s come to light is that the mechanism by which the “current” MLS label must be managed has a notably temporal aspect. That is to say that when a subject reads or writes data to an object its low MLS label must change to prevent data leakage. All subsequent accesses will then be made in the context of this new label. This is temporal because the sensitivity and categories returned by the functions and will change based upon the actions of the subject over time.
The management of subject and object labels (basically how they change over time) can, and probably should be a distinct and separate operation from the mechanism making access control decisions. In this way the reference monitor can still us this logic to prove which accesses should be allowed and another separate module using a completely different reasoning engine can be responsible for label management.
Next Time
This is the last of my posts on MLS in SELinux and representing access control decisions with logic. My next post will be about the work I’ve done implementing the sVirt requirements in a simulated environment to demonstrate the separation properties that can be obtained using MLS categories.


 .
. , short for “security level”. In previous examples this operator has returned the sensitivity level of the parameter (a principle). Now that we’re considering categories we’ll need an operator to return the category component of the principles security label.
, short for “security level”. In previous examples this operator has returned the sensitivity level of the parameter (a principle). Now that we’re considering categories we’ll need an operator to return the category component of the principles security label. which, much like
which, much like 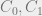 it would return:
it would return: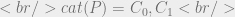
 if the principle has been assigned no categories.
if the principle has been assigned no categories. and
and  . We define their security labels like so:
. We define their security labels like so:
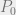 dominates that of
dominates that of