It’s been 5 months since my last post about my on-going project required by my masters program at SU. With the hope of eventually getting my degree, this is my last post on the subject. In my previous post on this topic I described a quick prototype I coded up to test an example program and SELinux policy to demonstrate the sVirt architecture. This was a simple example of how categories from the MCS policy can be used to separate multiple instances of the same program. The logical step after implementing a prototype is coding up the real thing so in this post I’ll go into some detail describing an implementation of the sVirt architecture I coded for the XenClient XT platform. While it may have taken me far too long to write up a description of this project, it’s already running in a commercial product … so I’ve got that going for me 🙂
Background
XenClient is a bit different than the upstream Xen in that the management stack has been completely rewritten. Instead of the xend process which was written in python, XenClient uses a toolstack that’s rewritten in Haskell. This posed two significant hurdles. First I’ve done little more than read the first few pages from a text book on Haskell so the sVirt code, though not complex, would be a bit over my skill level. Second SELinux has no Haskell bindings which would be required by the sVirt code.
Taking on the task of learning a new functional programming language and writing bindings for a relatively complex API in this language would have taken far longer than reasonable. Though we do intend to integrate sVirt into the toolstack proper, putting this work on the so called “critical path” would have been prohibitively expensive. Instead we implemented the sVirt code as a C program that is interposed between the toolstack and the QEMU instances it is intended to separate. Thus the toolstack (the xenmgr process) invokes the svirt-interpose program each time a QEMU process needs to be started for a VM. The svirt-interpose process then does all of the necessary functions to prepare the environment for the separation of the QEMU instance requested from the others currently running.
The remainder of this document describes the svirt-interpose program in detail. We begin by describing the interfaces down the call chain between the xenmgr, svirt-interpose and QEMU.
We then go into detail describing the internal workings of the svirt-interpose code. This includes the algorithm used to assign categories to QEMU processes and to label the system objects used by these processes. We conclude with a brief analysis of the remaining pieces of the system that could benefit from similar separation. In my first post on this topic I describe possible attacks we’re defending against so I’ll not repeat that here.
Call Chain
As we’re unable to integrate the sVirt code directly into the toolstack we must interpose the execution of the sVirt binary between the toolstack and QEMU. We do this by having the toolstack invoke the sVirt binary and then have sVirt invoke QEMU after performing the necessary SELinux operations. For simplicity we leave the command line that the toolstack would normally pass to QEMU unchanged and simply extract the small piece of information we need from it in the sVirt code. All sVirt requires to do it’s job is the domain id (domid) of the VM it’s starting a QEMU instance for. This value is the first parameter so extracting it is quite simple.
The final bit that must be implemented is in policy. Here we must be sure that the policy we write reflects this call chain explicitly. This means removing the ability for the toolstack (xend_t) to invoke QEMU (qemu_t) directly and replacing this with allowing the toolstack to execute the svirt-interpose program (svirt_t) while allowing the svirt-interpose domain to transition to the QEMU domain. This is an important part of the process as it prevents the toolstack from bypassing the svirt code. Many will find protections like this superfluous as it implies protections from a malicious toolstack and the toolstack is a central component of the systems TCB. There is a grain of truth in this argument though it represents a rather misguided analysis. It is very important to limit the permissions granted to a process to limit a possible vulnerability even if the process we’re confining is largely a “trusted” system component.
Category Selection
The central piece of this architecture is to select a unique MCS category for each QEMU process and assign this category to the resources belonging to said process. Before a category can be assigned to a resource we must first chose the category. The only requirement we have when selecting categories is that they are unique (not used by another QEMU process).
Thus there is no special meaning in a category number. Thus it makes sense to select the category number at random.
We’re presented with an interesting challenge here based on the nature of the svirt-interpose program. If this code was integrated with the toolstack directly it would be reasonable to maintain a data structure mapping the running virtual machines to their assigned categories. We could then select a random category number for a new QEMU instance and quickly walk this in-memory structure to be sure this category number hasn’t already been assigned to another process. But as was described previously, the svirt-interpose code is a short lived utility that is invoked by the toolstack and dies shortly after it starts up a QEMU process. Thus we need persistent storage to maintain this association.
The use of the XenStore is reasonable for such data and we use the key ‘selinux-mcs’ under the /local/domain/$domid node (where $domid is the domain id of a running VM) to store the value. Thus we randomly select a category and then walk the XenStore tree examining this key for each running VM. If a conflict is detected a new value is selected and the search continues. This is a very naive algorithm and we discuss ways in which it can be improved in the section on future work.
Object labeling
Once we’ve successfully interposed our svirt code between the toolstack and QEMU and implemented our category selection algorithm we have two tasks remaining. First we must enumerate the objects that belong to this QEMU instance and label them appropriately. Second we must perform the steps necessary to ensure the QEMU process will be labeled properly before we fork and exec it.
Determining the devices assigned to a VM by exploring the XenStore structures is tedious. The information we begin with is the domid of the VM we’re configuring QEMU for. From this we can examine the virtual block devices (VBDs) that belong to this VM but the structure in the VM specific configuration space rooted at /local/domain/$domid only contains information about the backend hosting the device. To find the OS objects associated with the device we need to determine the backend, then examine the configuration space for that backend.
We begin by listing the VBDs assigned to a VM by enumerating the /local/domain/$domid/device/vbd XenStore directory. This will yeild a number of paths in of the form /local/domain/$domid/device/vbd/$vbd_num where $vbd_num is the numeric id assigned to a virtual block device. VMs can be assigned any number of VBDs so we must process all VBDs listed in this directory.
From these paths representing each VBD assigned to a VM we get closer to the backing store by extracting the path to the backend of the split xen block driver. This path is contained in the key /local/domain/$domid/device/vbd/$vbd_num/backend. Once this path is extracted we check to see if the device in dom0 is writable by reading the ‘mode’ value. If the mode is ‘w’ the device is writable and we must apply the proper MCS label to it. We ignore read only VBDs as XenClient only assigns CDROMs as read only, all hard disks are allocated as read/write.
Once we’ve determined the device is writable we now need to extract the dom0 object (usually a block or loopback device file) that’s backing the device. The location of the device path in XenStore depends on the backend storage type in use. XenClient uses blktap processes to expose VHDs through device nodes in /dev and loopback devices to expose files that contain raw file systems. If a loopback device is in use the path to the device node will be stored in the XenStore key ‘loop-device’ in the corresponding VBD backend directory. Similarly if a bit more cryptic, the device node for a blktap device for a VHD will be in the XenStore key ‘params’.
Once these paths have been extracted the devices can be labeled using the SELinux API. To do so, we first need to know what the label should be. Through the SELinux API we can determine the current context for the file. We then set the MCS category calculated for the VM on this context and then change the file context to the resultant label. Important to note here is that both a sensitivity level and a category must be set on the security context. The SELinux API doesn’t shield us from the internals of the policy here and even though the MCS policy doesn’t reason about sensitivities there is a single sensitivity defined that must be assigned to every object (s0).
Assigning a category to the QEMU process is a bit different. Unlike file system objects there isn’t an objct that we can query for a label. Instead we can ask the security server to calculate the resultant label of a transition from the current process (sVirt) to the destination process (QEMU). There is an alteernative method available however and this allows us to deterine the type for the QEMU process directly. SELinux has added some native support for virtualization and one such bit was the addition of the API call ‘selinux_virtual_domain_context_path’. This function returns the path of a file in the SELinux configuration directory that contains the type to be assigned to domains used for virtualization.
Once we have this type the category calculated earlier is then applied and the full context is obtained. SELinux has a specific API call that allows the caller to request the security server apply a specific context to the process produced by the next exec performed by the calling process (setexeccon). Once this has been done successfully the sVirt process cleans up the environment (closes file descriptors etc) and execs the QEMU program passing it the unmodified command line that was provided by the toolstack.
Conclusion
Applying an MCS category to a QEMU process and its resources is fairly straight forward task. There are a few details that must be attended to to ensure that proper error handling is in place but the code is relatively short (~600 LOC) and quite easy to audit. There are some places where the QEMU processes must overlap however. XenClient is all about multiplexing shared hardware between multiple virtual machines on the same PC / Laptop. Sharing devices like the CD-ROM that is proxied to clients via QEMU requires some compromise.
As we state above the CD-ROM is read-only so an MCS category is not applied to the device itself but XenClient must ensure the accesses to the device are exclusive. This is achieved by QEMU obtaining an exclusive lock on a file in /var/lock before claiming the CD-ROM. All QEMU processes must be able to take this lock so the file must be created without any categories. This may seem like a minor detail but it’s quite tedious to implement in practice and it does represent path for data to be transmitted from one QEMU process to another. Transmission through this lock file would require collusion between QEMU processes so it’s considered a minimal threat.
Future Work
This is my last post in this series that has nearly spanned a year. I’m a bit ashamed it’s taken me this long to write up my masters project but it did end up taking on a life of its own getting me a job with Citrix on the XenClient team. There’s still a lot of work to be done and I’m hoping to continue documenting it here. Firstly I have to collect the 8 blog posts that document this work and roll them up into a single document I can submit to my adviser to satisfy my degree requirements.
In parallel I’ll be working all things XenClient hopefully learning Haskell and integrating the sVirt architecture directly into our toolstack. Having this code in the toolstack directly will have a number of benefits. Most obviously it’ll remove a few forks so VM loading will be quicker. More interestingly though it will open up the possibility of applying MCS category labeling to devices (both PCI and USB) that are assigned to VMs. The end goal, as always, is strengthening the separation between the system components that need to remain separate thus improving the security of the system.
 operator denotes dominance:
operator denotes dominance:
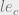
 and
and 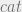 operators to access the low and high parts of the range respectively.
operators to access the low and high parts of the range respectively.

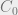 and
and  . Regardless we’ve got enough information to do begin a proof with the aims to satisfy the left side of the read implication, which, in plain english, requires that the subjects low MLS label must dominate that of the object.
. Regardless we’ve got enough information to do begin a proof with the aims to satisfy the left side of the read implication, which, in plain english, requires that the subjects low MLS label must dominate that of the object.
 from these assumptions. This is because we would need to derive the left side of the
from these assumptions. This is because we would need to derive the left side of the 




 then the reference monitor can conclude
then the reference monitor can conclude 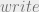 (allow the
(allow the 






 .
. , short for “security level”. In previous examples this operator has returned the sensitivity level of the parameter (a principle). Now that we’re considering categories we’ll need an operator to return the category component of the principles security label.
, short for “security level”. In previous examples this operator has returned the sensitivity level of the parameter (a principle). Now that we’re considering categories we’ll need an operator to return the category component of the principles security label. which, much like
which, much like 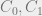 it would return:
it would return: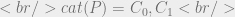
 if the principle has been assigned no categories.
if the principle has been assigned no categories. and
and  . We define their security labels like so:
. We define their security labels like so:
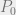 dominates that of
dominates that of 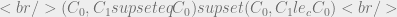


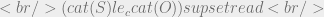





 . Like
. Like 


 . For a given object O that is classified Secret we would say:
. For a given object O that is classified Secret we would say:
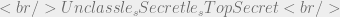
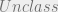 principle. Combining these two operators we can now describe these relationships in an access control scenario.
principle. Combining these two operators we can now describe these relationships in an access control scenario.
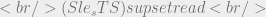
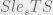 is true by the ordering we’ve defined and our knowledge of logical implication (modus ponens WHAT!) we can deduce
is true by the ordering we’ve defined and our knowledge of logical implication (modus ponens WHAT!) we can deduce 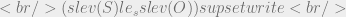
 and
and  will again be top secret and secret respectively. Thus:
will again be top secret and secret respectively. Thus:
