There are two parts to a Multi-Level Secuirty (MLS) policy. Now that we’ve covered the sensitivity component it’s time to address the second component which is typically referred to as a category or compartment. Before we get into the rules that govern this policy component however, let’s talk about why we need them.
Sensitivities are a direct reflection of military policy for classifying sensitive data. What’s not typically known is that within each sensitivity level (Unclassified, Secret, Top Secret) there are many sub-compartments for protecting different types of data. An example in the military context would be data about political or diplomatic subjects and data about signal intelligence collection activities.
People working on sensitive data in these different areas of interest likely don’t have any need to access the other category even though both sets of data are at the same sensitivity level. The need for this additional level of separation resulted in the creation of this second component of the policy model.
Categories / Compartments
The oldest publication that I could find describing a reference monitor expected to enforce MLS categories is from a document describing the ADEPT-50 time sharing system [1]. This system was implemented as one of the first remotely accessible (terminal) main frames enforcing a military security policy. Unfortunately the ACM wants $15 for the paper which is pretty steep for the casual reader. If your company / university / local library has an ACM subscription then you should definitely pull down this article. It’s a great read.
If you can’t get the article, the relevant parts have been covered in other places. I’d specifically recommend the SELinux Wiki [2] which is accurate and relevant if a bit sparse. Further, Chin and Older [3] also give the topic consideration and apply the similar rules.
From these sources we know that a subject must poses a superset of the categories assigned to the object it wishes to access for a read operation to be granted. We represent the subset relationship where set A is a subset of set B like so:

Similarly we can flip the relationship around and say that B is a superset of A like so:

Using the language developed previously, we would say that B dominates A if 
Note: these are not proper subsets, the relationship holds if A and B are the same set.
The Logic
Now that we’ve established the rules governing the category component of an MLS policy let’s incorporate these rules into the logic. I’ve been using operators and logic from [3] specifically 
For this we define the function 
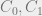
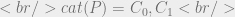
Note: the categories assigned to P may be the empty set: 
Now that we have a way to obtain the necessary information about principles we need an operator to compare them. Again we use the operator 
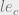



With this information we can conclude that the security label for 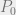
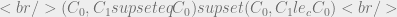
We generalize this implication as:

Recalling our discussion of sensitivity levels and the slev operator we would say that principle

For now we’ll assume the sensitivity levels of our principles are all the same so we can focus on the categories alone.
Example: Reading a file
Now that we have all the necessary logic we can construct a more complete example. Considering a read operation, our goal is (as the reference monitor) to prove that the security label of our subject S dominates that of our object O so that we can conclude access should be granted. We represent this as the logical expression:
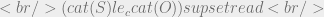
Now we need to make some assumptions about the system, specifically defining the categories assigned to the principles S and O (subject and object respectively):

From these assumptions we can show that, using the above logic, the categories assigned to S dominate those of O:

With this we can conclude (by modus ponens) that this read operation will be allowed

Writing to a file
The rules governing file reads is straight forward: if a subject with the two categories 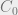

In [1] the authors address this concern for file creation using a “high-water mark” created from a history of all files accessed by a job / process. They do not however differentiate between read and write access on a file. Presumably the high-water mark method would also work for file writes but it would require the reference monitor to track the data categories accessed by a process and ensure that all files written be labeled with the full set of categories previously read by the process.
This loosely stated rule would be quite complex when implemented. It would require a full history of the categories accessed by a process be maintained in the kernel and that this be done for each process. For some processes this list would get quite long and take up significant storage.
An alternative approach is simply to trust the subject to write only data of the appropriate category to the file. This isn’t very viable as it has a significant short fall discussed above. Generally any approach that is described with the phrase “trust the subject” will be rejected by security auditors.
Finally the most restrictive approach would be to require a subject writing to an object to have the same set of categories as the object. This seems like the best approach as far as security is concerned but it is very restrictive and could cause over classification of newly created files if the user is not diligent.
Conclusion
The concept of categories / compartments from MLS policy fits naturally into the logic we’ve been using to reason over sensitivities in my previous posts. It’s a simple concept based on set comparisons that a reference monitor can do quickly and efficiently. This policy’s application to reading files is simple but the best way to handle writes comes with significant complications which we discussed here briefly.
Instead of trying to solve this last complication in this post I’m punting. In my next post however we’ll get into the SELinux policy. We’ll take a look at how they deal with categories in the reference policy focusing on the read operation to make concrete the logic from this post. Then we’ll move on to how refpol deals with categories in file write operations hopefully shedding some light on how a real system manages the complexity discussed in the last section of this post.
References
1 C. Weissman. 1969. Security controls in the ADEPT-50 time-sharing system. In Proceedings of the November 18-20, 1969, fall joint computer conference (AFIPS ’69 (Fall)). ACM, New York, NY, USA, 119-133. DOI=10.1145/1478559.1478574 http://doi.acm.org/10.1145/1478559.1478574
2 SELinux Wiki. Managing Security Levels via Dominance Rules. http://selinuxproject.org/page/NB_MLS#Managing_Security_Levels_via_Dominance_Rules
3Chin, Shiu-Kai and Older, Susan. Access Control, Security and Trust CRC Press, 2011. http://www.amazon.com/Access-Control-Security-Trust-Cryptography/dp/1584888628

One thought on “Understanding Multi-Level Security part #3”