In my last post I introduced a topic I’ve been working on over the past year. That post provided a description of the problem and it’s importance, but didn’t get into the details behind the technologies used in the solution I’ve worked up. This post is the first of several to come that will fill in these details.
Purpose
I’ve been having a hard time sorting out the best way to present the relatively complex topic of computer security policy and it’s application to my specific project. My first few attempts to write this up resulted in some very convoluted ramblings.
It seemed like I was starting in the middle and missing all the background. Hoping to fix this I’m starting from the beginning with a quick explanation of the security policy that’s at the core of my project: military security policies and their implementation in SELinux.
To explain this I’m using a logical framework put forward by Chin and Older in their recent book [1]. I took a class with Dr. Chin this past fall and was particularly impressed with the contents of the book and the clear, concise syntax they developed.
Classifications
Everyone who’s seen a good spy movie has heard references to military security policy. I think it’s safe to day that every James Bond or Jason Bourne movie made a few references to Unclassified, Secret or Top Secret data. These are typically referred to as classifications or sensitivity levels in the literature. Everyone who’s seen these movies understands what the policy is, but few people have a solid grasp on the mathematical rules that govern access control systems implementing this policy.
It really is as simple as it seams though and easy to explain in the context of subjects (generally people or computer processes acting on their behalf) and objects (either physical or electronic). There are two governing principles [2]:
- the simple security property: a subject operating at a given sensitivity level can read objects at the same level or below
- the ★-property: a subject operating at a given sensitivity level can write to objects at the same level or higher
A computer system that implements these two rules is said to implement a multi-level security (MLS) policy.
Inherent in these two rules is a partial ordering among classification labels. Chin and Older describe this ordering by first defining a function that produces the sensitivity of a principle or object:  . For a given object O that is classified Secret we would say:
. For a given object O that is classified Secret we would say:

They also define an operator:  that describes the relationship between two sensitivity levels. Going back to the sensitivity levels we’re so familiar with we would say:
that describes the relationship between two sensitivity levels. Going back to the sensitivity levels we’re so familiar with we would say:
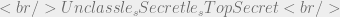
Simply put a TopSecret principle is more sensitive than (or dominates) a Secret principle, which dominates an 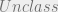 principle. Combining these two operators we can now describe these relationships in an access control scenario.
principle. Combining these two operators we can now describe these relationships in an access control scenario.
The Simple Security Property
Getting back to the security properties for military data we can use the above syntax to describe the system. The simple security property requires that a subject operating at a given security level can read objects at the same level or below. We’d such a situation as:

Above we assume the ‘O’ and ‘S’ are an object and a subject in our system respectively. By the definition of  we know it returns the sensitivity level of its parameter so let’s say that object O is classified Secret and subject S is classified Top Secret. We could then say:
we know it returns the sensitivity level of its parameter so let’s say that object O is classified Secret and subject S is classified Top Secret. We could then say:
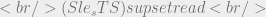
Knowing that 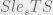 is true by the ordering we’ve defined and our knowledge of logical implication (modus ponens WHAT!) we can deduce
is true by the ordering we’ve defined and our knowledge of logical implication (modus ponens WHAT!) we can deduce  from this for future use in our logical framework and we take this to mean a read operation would be granted. Chin and Older provide a more rigorous approach but for our purposes the short hand I’m using is sufficient (because I say so).
from this for future use in our logical framework and we take this to mean a read operation would be granted. Chin and Older provide a more rigorous approach but for our purposes the short hand I’m using is sufficient (because I say so).
The ★-Property
The ★-property requires that the sensitivity level of a subject is lower than or equal to that of the object for a write access to be permitted. We’d represent this as:
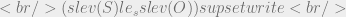
If ‘S’ and ‘O’ are the same subject and object as in the previous example the values of  and
and  will again be top secret and secret respectively. Thus:
will again be top secret and secret respectively. Thus:

Using the same partial ordering defined previously we can see that the first part of the implication here is false. This time from our knowledge of logical implication we can’t say anything about the term on the right (the 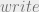 statement), so we cannot say a write would be granted. It would then be denied by any sane access control implementation. Again I’m using short hand.
statement), so we cannot say a write would be granted. It would then be denied by any sane access control implementation. Again I’m using short hand.
Conclusion
This brief introduction was an attempt to frame basic MLS constructs in a simple logic developed by Chin and Older. Alone this post won’t mean much to most people but it’s intended as a foundation. In my next post I’ll introduce SELinux constraints, MLS constraints and use the logic from this post to illustrate how a reference monitor would evaluate constraints in an access control decision.
References
1 Chin, Shiu-Kai and Older, Susan. Access Control, Security and Trust CRC Press, 2011.
2 Bell, David Elliott and LaPadula, Leonard J. Secure Computer Systems: A Mathematical Model, MITRE Corporation, 1973.
3 Chad Hanson, SELinux and MLS: Putting the Pieces Together, TCS











