In my last post I gave a brief description of the two governing principles of Multi-Level security. I then used a short-hand version of a logical framework from Chin and Older to explain how a reference monitor may use such a logic to make access control decisions.
In this post I go one step further to look at the MLS component of SELinux policy. I’ll relate the MLS constraints from SELinux to the logical framework from Chin and Older and show how I’ve used their syntax to help debug SELinux denials (AVC denied) in my own policy writing.
SELinux
The type enforcement (TE) model implemented in SELinux is very different from that of the MLS model. TE is a completely different approach to confining subjects and objects. Interesting enough though, to remain relevant in the government space (i.e. to get Common Critieria certified at the EAL4 level against the LSPP), SELinux was extended with the mechanisms necessary to implement an MLS policy. A significant portion of this work was done by TCS and is documented in a brief white-paper [1].
This paper describes the changes to the SELinux implementation in the kernel that were necessary, but assumes the reader is intimately familiar with government security policy. To fill that gap I’ve taken the logical rules from Chin and Older described previously and used them to explain the constraints that implement the MLS policy in SELinux.
SELinux Constraints
WE’ll start with a brief description of the SELinux constraint syntax. The interested reader I’ll refer the to the base constraint file in the SELinux source tree: $SELINUX_SRC/policy/constraints. In short, constraints allow for the policy author to define additional rules that must be satisfied beyond the SELinux type enforcement policy.
Let’s start with a simple example:
constrain dir_file_class_set { create relabelto relabelfrom }
(
u1 == u2
or t1 == can_change_object_identity
);
The first keyword is constrain which simply identifies the constraint. Next comes a set of object types, followed by a set of permissions. When making an access control decision the security server will look at the requested permission and the object type and if they both are members of these sets the constraint will be evaluated. The constraint itself is a simple set of logical expressions. The parameters available for use in these expressions are the user, role and type component of the labels of both subject and object in the request. Components of the subject label are suffixed with 1, objects with 2.
In the expression above we see that the constraint requires that for a file or directory to be created or relabeled the user component of the subject and object labels cannot change (thus they must be equal or ==).
ASIDE: This constraint may seem like a mundane detail but it’s actually quite significant. Historically UNIX operating systems allowed users with sufficient privileges to change their identity to that of another user to perform administrative tasks. This constraint says that SELinux will never allow the user to change their identity (in the SELinux context) making attribution possible.
Examining the constraint further we see there is a loop hole that allows a subject with a specific type attribute (can_change_object_identity in this case) to change the user identity on a file or directory. Loop holes like this are unfortunate but are required for real systems to function.
MLS Constraints
The rules for MLS Constraints are the same as standard constraints. The only differences are:
- subject and object labels available for use have the additional MLS label components
- new operators which allow for the comparison of sensitivity labels
The MLS components of the SELinux labels come in two parts: the low clearance and the high clearance. These are pretty self explanatory as they represent the lowest possible clearance for a principle and the highest clearance the principle may access.
The new operators are:
- eq: two MLS label components are equal
- dom: one MLS label component dominates another
- domby; same as dom but reversed
- incomp: two MLS label components are incomparable
I’ll explain the important operators as well as an essential MLS property with an example:
mlsconstrain { dir file lnk_file chr_file blk_file sock_file fifo_file } { read getattr execute }
(( l1 dom l2 ) or
(( t1 == mlsfilereadtoclr ) and ( h1 dom l2 )) or
( t1 == mlsfileread ) or
( t2 == mlstrustedobject ));
This rule constraints read operations on a rather large set of object types. The first line of the statement is the expected simple security property: the low clearance of the subject must dominate the low clearance of the object. Simply put this allows subjects to read at or below their lowest clearance.
The second line allows a subject to read an object if it’s highest clearance dominates that of the object AND it’s type is that of ‘mlsfilereadtoclr’ which is short hand for ‘mls file read to clearance’. This is a special set of subjects that are allowed to read to their highest clearance if they’re operating with a ranged label. Most processes will run with only one MLS label so this constraint will rarely come into play except for processes like init.
The remainig two lines are again, types that allow for loop holes. A process with this type would be considered a “trusted process” in the literature which basically means it’s a process allowed to violate the security model. We’d prefer to have none of these if possible but they exist for a number of reasons. These could be poorly coded software that can’t be fixed by those who care about these things because they’re proprietary or they’re simply processes that must violate MLS to perform their task.
Evaluating MLS Constraints in the logic
Using the logic presented in my previous post to reason through an access control decision based on the above SELinux constraints requires we have a way to evaluate expressions using the operators from the constraint language. I’ll address them in the order they’re presented above:
- eq: equality
Testing the equality of two sensitivity levels is straightforward. Using the  operator we get the sensitivity of a principle and then compare the two using a simple comparison of the strings from our partial ordering. If our reference monitor is optimized it may map the strings to integers (as is the case with SELinux) for a faster comparison but the principle holds.
operator we get the sensitivity of a principle and then compare the two using a simple comparison of the strings from our partial ordering. If our reference monitor is optimized it may map the strings to integers (as is the case with SELinux) for a faster comparison but the principle holds.
- dom: dominance
This operator is well developed by Chin and Older in their  operator and was the subject of my previous post.
operator and was the subject of my previous post.
- domby: variation on dominance
This is simply the reverse of the dominance rule and I think it’s included as syntactic sugar.
- incomp: incomparable
This operator is only valid when considering the category component of an MLS label and is deferred for future discussion of the Multi-Category Security (MCS) policy.
Now that the operators are sorted out we can use the constraint in an access control decision. I’m using short hand just to keep this post from turning into a book so the logicians among your may groan a bit …
First we must state the partial ordering for secrecy lables in our system. These should be familiar by now:

Next we define a subject and an object in our system and assign them both secrecy levels:

Now that we’ve defined an Unclassified object and a Secret subject we can revisit the simple security property and the additional rules from the SELinux MLS constraint. I’m going to make up some functions and operators out of thin air so brace yourselves:

First I’ve augmented the function such that it can deal with principles having a high and low sensitivity level. I’ve done so by adding a subscript of ‘l’ for the low sensitivity and an ‘h’ for the high sensitivity.
Second I’ve added another function similar to called  . Like it allows us to access a component of the security label for a principle. Instead of the classification however it returns the type component of the SELinux label. For the sake of completeness lets give our subject and object types:
. Like it allows us to access a component of the security label for a principle. Instead of the classification however it returns the type component of the SELinux label. For the sake of completeness lets give our subject and object types:

Now to it’s just a matter of putting it all together. First from the type and sensitivity assignments for our subject ‘S’ and object ‘O’ we can replace instances of and . I’ve only defined one sensitivity label for each object so both low and high labels are the same.

Since neither neither subject or object we’re considering have the types listed in this constraint we can quickly mark those comparisons as failing. Further we can simplify terms that have become ‘false’ and we get:

In this simple case we’ve reduced the constraint to the simple security property. Further using the partial ordering we’ve defined we can see that Secret dominates Unclassified and our read request should be allowed by the reference monitor.
Conclusion
This very brief exercise shows the application of a relatively new logical framework to the analysis of a specific SELinux MLS constraint. I’ve found this type of reasoning extremely useful in debugging MLS policy as the available tools (audittoallow) provide no useful information about denials caused by constraints. The exercise performed in this post is equally applicable to any other MLS constraint from the reference policy so if you’re interested give it a try with the constraint for common write operations on files and prove the ★-property.
Up next is the MCS policy …
References
1 Chad Hanson, SELinux and MLS: Putting the Pieces Together, TCS





 . For a given object O that is classified Secret we would say:
. For a given object O that is classified Secret we would say:
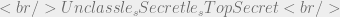
 principle. Combining these two operators we can now describe these relationships in an access control scenario.
principle. Combining these two operators we can now describe these relationships in an access control scenario.
 we know it returns the sensitivity level of its parameter so let’s say that object O is classified Secret and subject S is classified Top Secret. We could then say:
we know it returns the sensitivity level of its parameter so let’s say that object O is classified Secret and subject S is classified Top Secret. We could then say: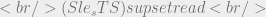
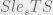 is true by the ordering we’ve defined and our knowledge of logical implication (modus ponens WHAT!) we can deduce
is true by the ordering we’ve defined and our knowledge of logical implication (modus ponens WHAT!) we can deduce  from this for future use in our logical framework and we take this to mean a read operation would be granted. Chin and Older provide a more rigorous approach but for our purposes the short hand I’m using is sufficient (because I say so).
from this for future use in our logical framework and we take this to mean a read operation would be granted. Chin and Older provide a more rigorous approach but for our purposes the short hand I’m using is sufficient (because I say so).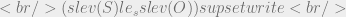
 and
and  will again be top secret and secret respectively. Thus:
will again be top secret and secret respectively. Thus:
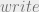 statement), so we cannot say a write would be granted. It would then be denied by any sane access control implementation. Again I’m using short hand.
statement), so we cannot say a write would be granted. It would then be denied by any sane access control implementation. Again I’m using short hand.






